CloudFront Analytics
2019-10
You’re reading a static website stored in S3 and served out of CloudFront. I recently set up web analytics for it with:
- CloudFront access logs stored in S3
- The AWS Athena analytics engine running SQL queries on that data
I now get analytics with flexible SQL queries:
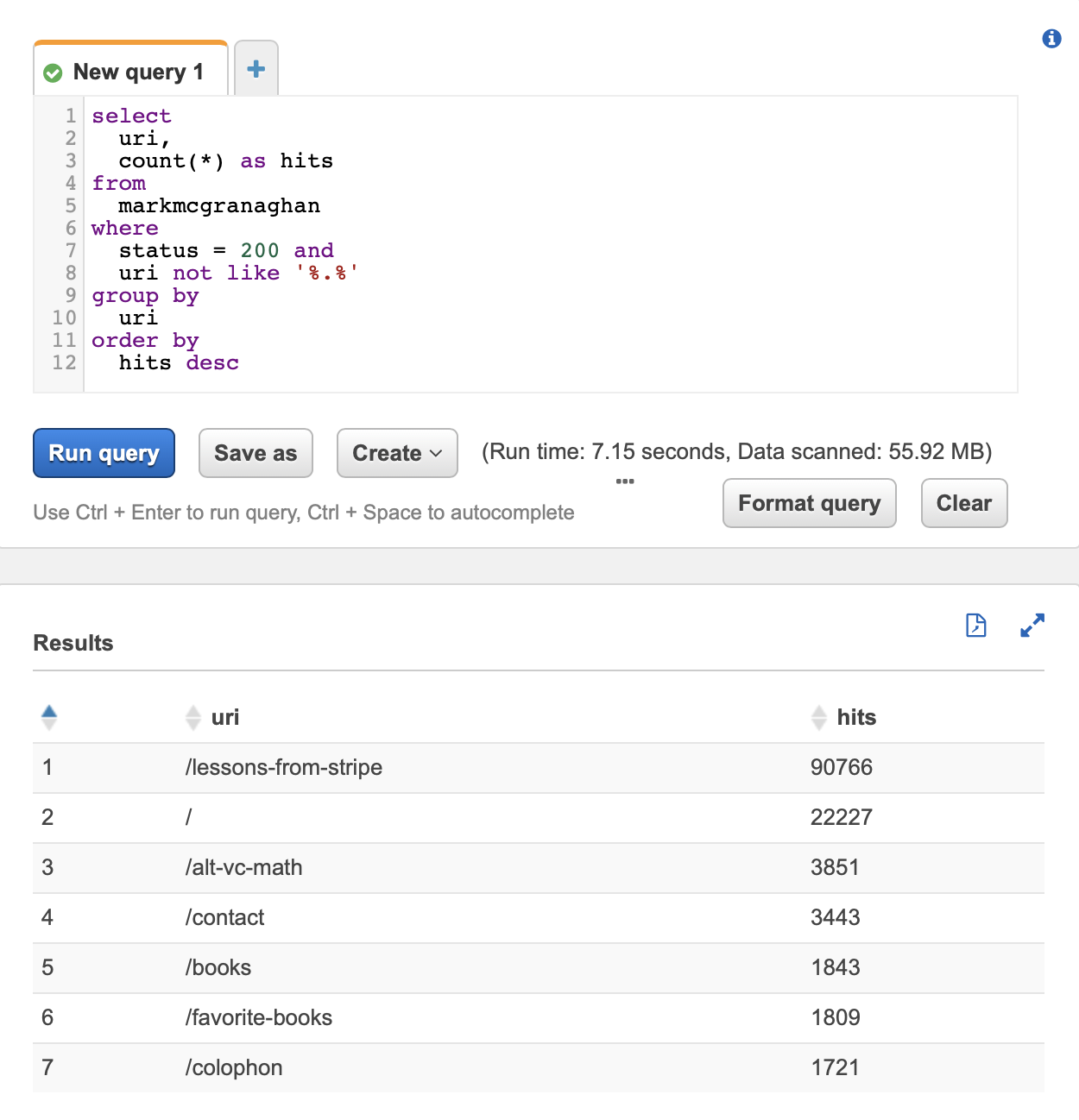
This proved a solid approach. There’s no software I need to manage, no client-side JavaScript, and no third-party providers beyond AWS. Here’s how I set it up and use it.
Sending CloudFront logs to S3
First we need to store CloudFront access logs in S3. As a bonus, we’ll have this raw data if we want to analyze it outside of Athena later.
Ensure you have an S3 bucket to use for logs. I use one bucket for all my sites, with a directory for each site:
Then in the CloudFront distribution for your site, enable access logging into that bucket (and into the appropriate directory if you’re using that setup):

Cloudfront will deposit access logs in that directory every few minutes, assuming you have non-zero traffic. Here’s what mine look like:

If you download, decompress, and view one of those files, you’ll see lines of tab-seperated data, one per request to CloudFront. Each line will have the request URL, HTTP method, referrer, and so on.
The appeal of the Athena approach is that you can run SQL queries directly against these compressed log files in S3 with standard SQL. Let’s look at that next.
Querying web access logs in Athena
Now head over to Athena in the AWS console and create a database to use for your CloudFront analytics. I called mine “cloudfront”:

Create a table that points to your data in S3, using this query template, with your S3 location sub’d in. This query also shows the fields you’ll have access to in your SQL queries:
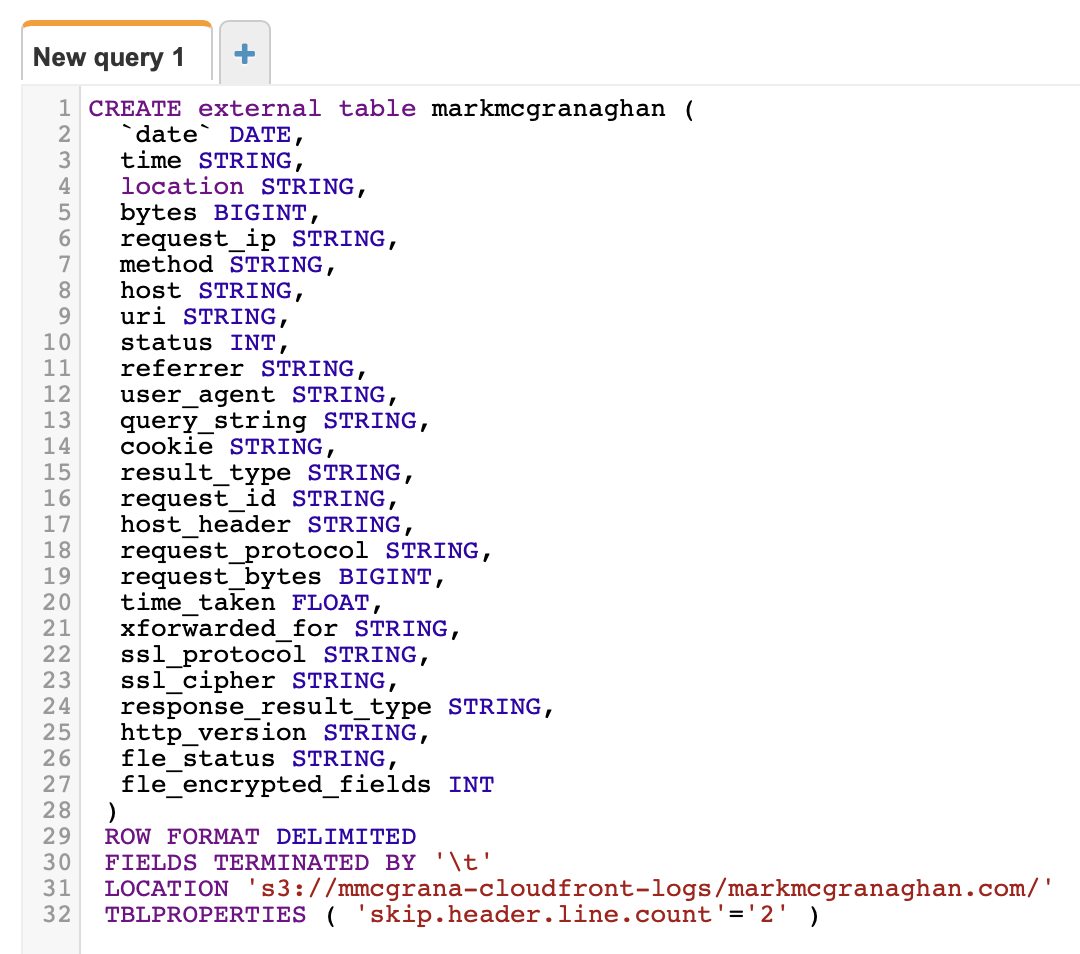
That’s it, you’re ready to run some queries. Here’s one I use to measure total monthly traffic to the site:
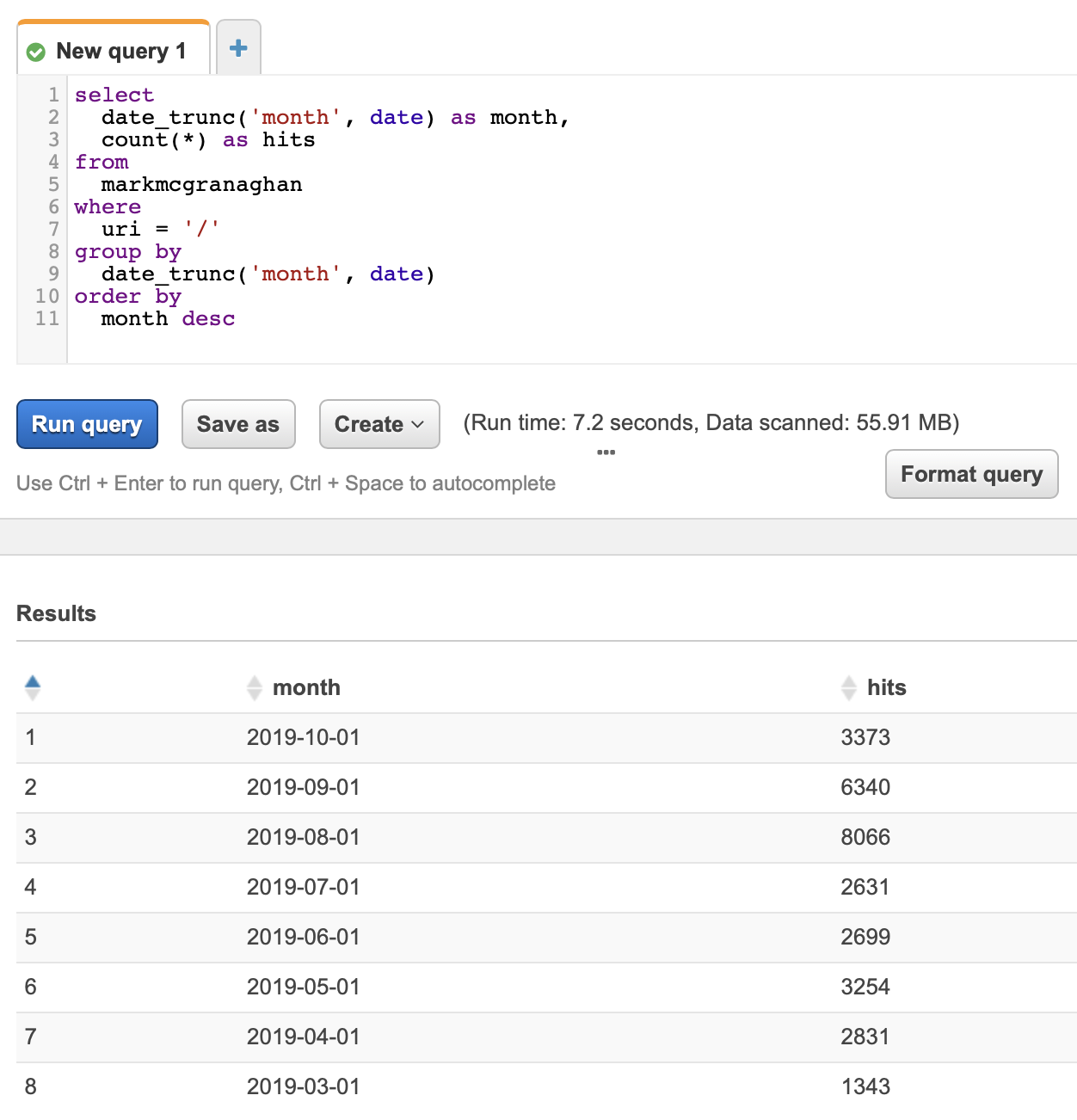
Note that even though this query covers data from thousands of individual compressed files in S3, it runs in a few seconds.
You should carefully examine your data to be sure you’re getting the right results. For example some requests are from Googlebot and you may want to exclude those from your queries.
Overall I’ve been very happy with this analytics setup. I recommend it for anyone running a static site looking for basic analytics without the downsides of client-side JavaScript, additional third parties providers, or more software to run themselves.
If you have thoughts on the setup, send them over!